Abstract
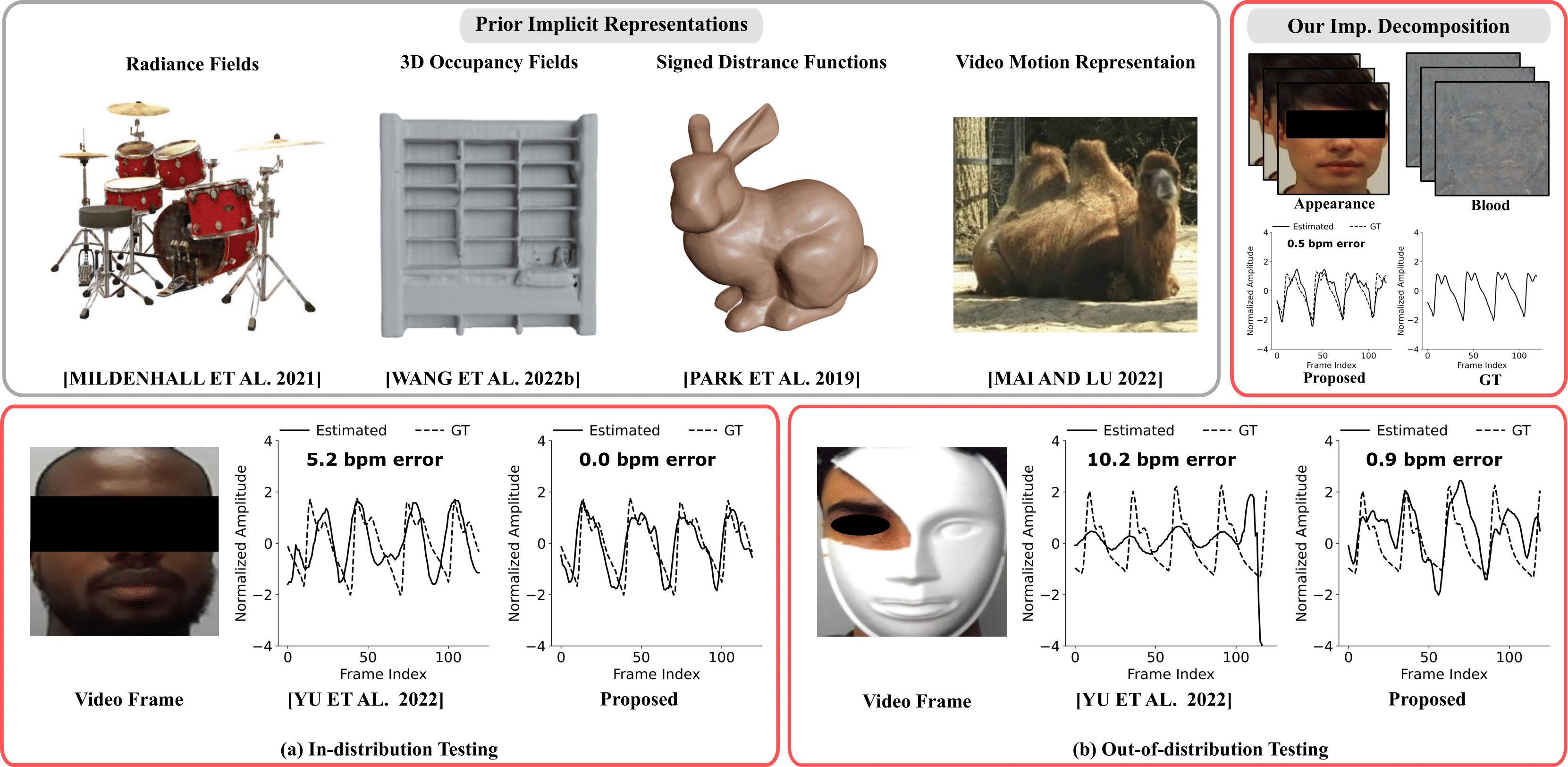
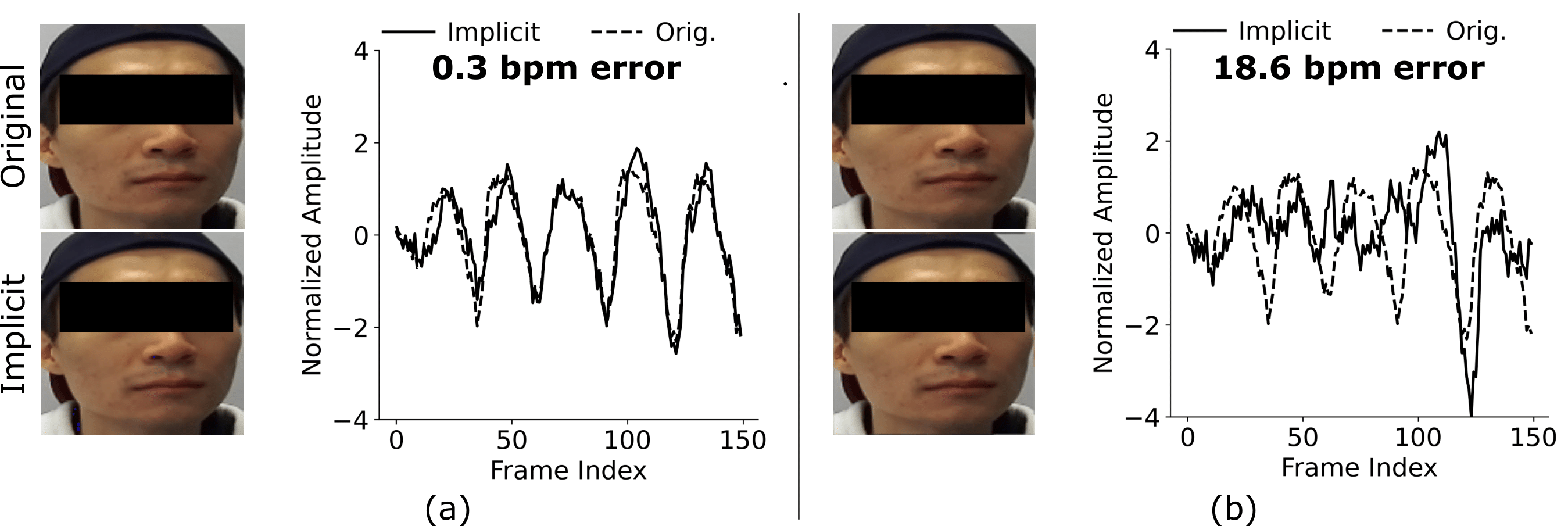
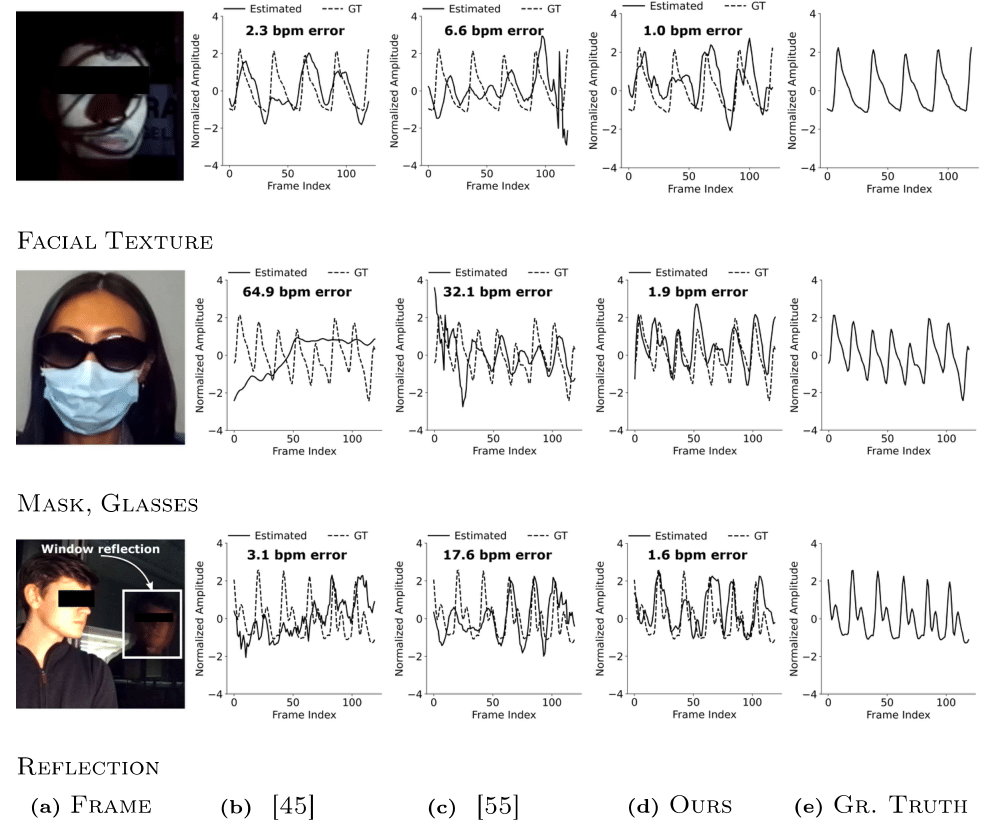
Scene representation networks, or implicit neural representations (INR) have seen a range of success in numerous image and video applications. However, being universal function fitters, they fit all variations in videos without any selectivity. This is particularly a problem for tasks such as remote plethysmography, the extraction of heart rate information from face videos. As a result of low native signal to noise ratio, previous signal processing techniques suffer from poor performance, while previous learning-based methods have improved performance but suffer from hallucinations that mitigate generalizability. Directly applying prior INRs cannot remedy this signal strength deficit, since they fit to both the signal as well as interfering factors. In this work, we introduce an INR framework that increases this plethysmograph signal strength. Specifically, we leverage architectures to have selective representation capabilities. We are able to decompose the face video into a blood plethysmograph component, and a face appearance component. By inferring the plethysmograph signal from this blood component, we show state-of-the-art performance on out-of-distribution samples without sacrificing performance for in-distribution samples. We implement our framework on a custom-built multiresolution hash encoding backbone to enable practical dataset-scale representations through a 50x speed-up over traditional INRs. We also present a dataset of optically challenging out-of-distribution scenes to test generalization to real-world scenarios.